
Reference tests are semantic regression tests
While most traditional software development now follows some form of test-driven development (TDD), most data-analysis and data-science developments do not. TDDA’s notion of reference testing is an approach to testing analytical processes that is designed to go better with the grain of analytical projects.
Two things are true of almost every analytical data project:
The basic idea of reference testing is that once an analytical result is considered good enough to use, believe, or ship, examples used to develop the analysis should be packaged up as tests that can be run again later, as illustrated below
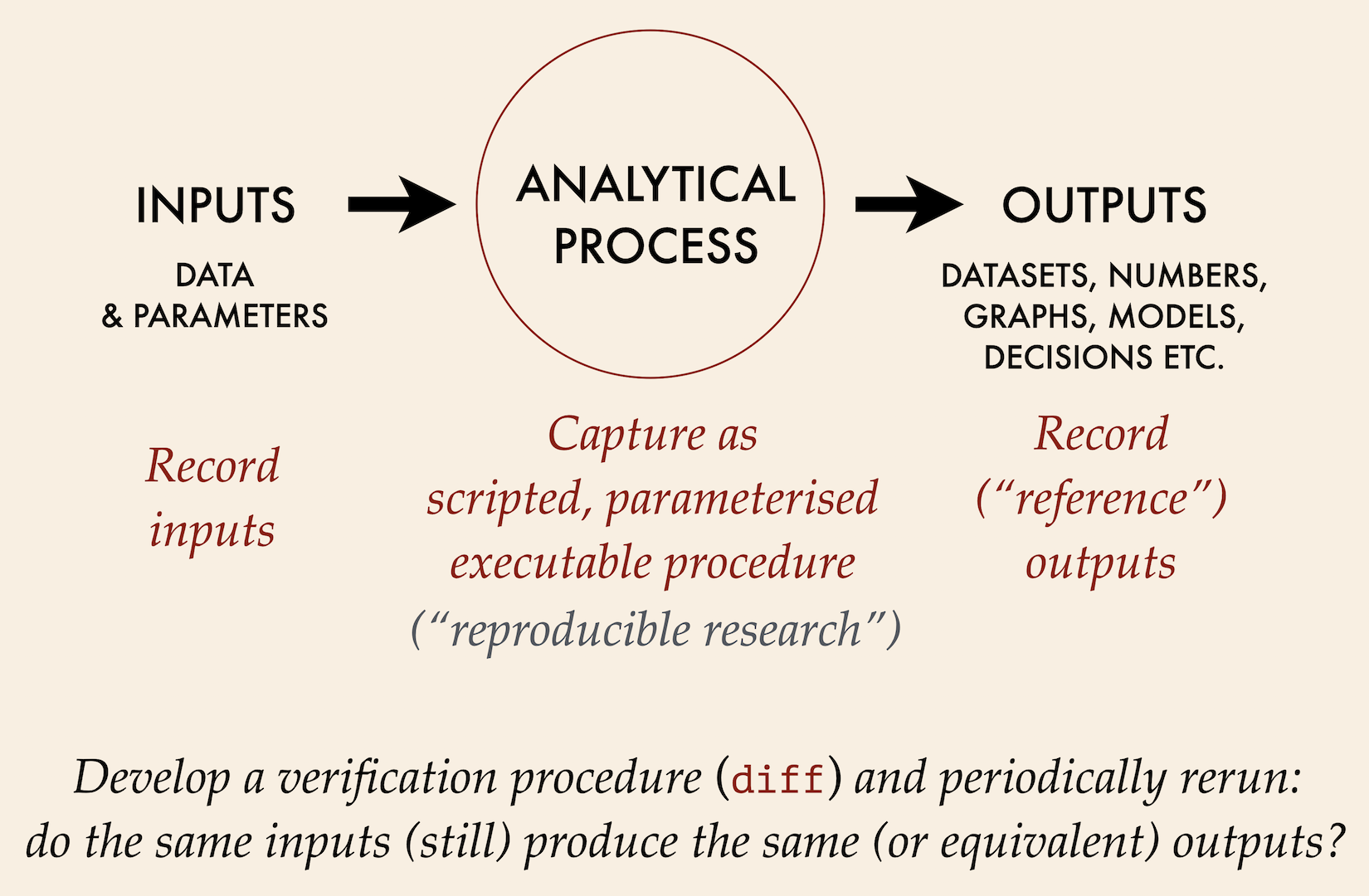
A reference test verifies that when the process is run again the same inputs produce equivalent outputs. It should be run either under continuous integration or whenever an analytical pipeline is re-used. Reference tests are a powerful means of noticing when a pipeline has rusted or suffered a regression, and when this is combined with good data validation throughout a pipeline and defensive programming, the robustness of analytical processes are much increased.
Our open-source tdda library provides two major kinds of support for reference testing:
unittest (Python’s standard testing
library) and pytest (a popular alternative) providing
much richer assertions for testing semantic equivalence,
together with support for a workflow better suited to analytical processes;tdda gentest command-line tool for writing reference tests
for analytical software (which can be written in any language,
not just Python).Simple unit tests usually check some small, easy-to-compute result or behaviour that is identical for a given set of inputs, and many proponents of test-driven development place most of the emphasis on unit tests, while also advocating for some high-level tests of larger components, systems and integrations.
When we talk about semantic equivalence (or semantic equality) we mean that the result is the same in all meaningful respects, but may not be byte-for-byte identical to a reference result. When comparing tabular data, we have comparisons that allow specification of acceptable differences, These can include:
Similarly, when comparing textual data, examples of allowed variation include
These sorts of semantic comparisons allow easy creation of powerful tests of outputs that would otherwise require significant custom code each time. Reducing the burden of test creation makes it more likely that analysts will actually write proper tests, which is less likely when doing so is onerous.
The tdda library also provides variations for comparing
The assertions also write out in-memory versions and suggest diff commands
when a test fails. These and related features make working with complex
results much more convenient.
The tdda gentest command-line tool writes tests for software in any
language, and can create tests for things like
Gentest provides both a Wizard to step through the process of creating
a test for a script or program, with inputs and parameters, and also
a command-line tool that allows all options to be provided as parameters
to a single command.
Although Gentest was initially developed as a demonstrator for tdda’s
reference-testing functionality, it has turned out to be remarkably powerful
particularly for test-driven document development
(TDDD).
Gentest works by running the code you provide, usually more than once.
It examines your environment and variations in output to write tests
that are often semantic rather than simple assertEqual statements.
Sometimes the tests need a small amount of tweaking, but Gentest
frequently writes better tests than people and usually gives a good
starting point.
The tdda
library is free and open source, so you can just use it,
but if you are looking to improve the testing and robustness of
analytical pipelines and processes, we can help,
whether with training, review, auditing, or implementation.